
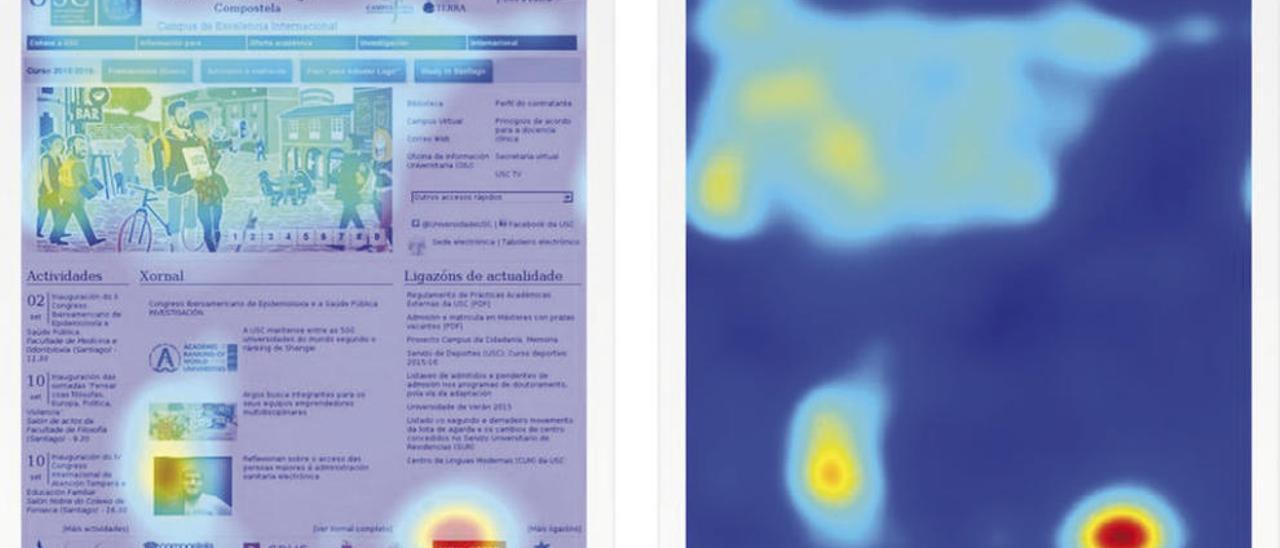
Cuando nos ponen delante una imagen, tanto fija como en movimiento, el cerebro humano actúa habitualmente de una misma manera, fijando su atención en unas zonas concretas y obviando otras. Conocer de antemano cuáles van a ser las partes preferidas de un cartel publicitario, de la portada de un periódico o de una página web ayudaría enormemente a sus creadores para decidir cómo y dónde ubicar los contenidos que más les interesa resaltar.
Un grupo de investigadores del Centro de Investigación en Tecnoloxías da Información (CiTIUS), en Santiago, ha desarrollado un algoritmo que permite anticipar las zonas de una imagen a las que dirigirá su mirada un espectador, además de reducir su exceso de información. Este modelo de atención visual lo podrían aplicar algunas empresas de publicidad en sus anuncios, aunque sus creadores también apuntan a posibles aplicaciones en el mundo de la Medicina.
"El modelo de atención visual -bautizado como Adaptive Whitening Saliency (AWS)- responde al problema del exceso de información en el ámbito de la robótica, ya que permite filtrar el ruido, es decir, la información que no es importante, pero además sirve de referencia para detectar las partes más significativas de una determinada imagen, incluso si ésta se encuentra en movimiento", explica Víctor Leborán, creador de este instrumento junto a los también físicos Xosé Manuel Pardo y Xosé Ramón Fernández Vidal y Antón García.
La representación visual de este resultado se llama "mapa de saliencia" y muestra las zonas más atractivas para el espectador. Los investigadores ofrecen de manera gratuita a cualquier persona la posibilidad de probar la herramienta a través de la página de la USC. Se trata de un demostrador en el que el interesado introduce su imagen y se le devuelve el mapa de saliencia que indica qué partes de la misma son más atractivas.
Pero, ¿cómo saben los investigadores que su modelo funciona? Para confirmarlo realizaron distintos estudios experimentales con miles de vídeos de distintas bases de datos que pusieron a ver a una serie de personas utilizando una seguidor ocular. "Se trata de poner a la persona ante una imagen, fija o vídeo, y la máquina extraer la posición del ojo y su movimiento; después, comparamos estos resultados con los que nos ofrece nuestro algoritmo y el resultado fue que es muy eficaz; estamos incluso sorprendidos de lo bien que funciona", destaca Leborán.
"Además, lo interesante de nuestro modelo es que es posible utilizarlo con cualquier tipo de imagen; el único requisito es que no haya un objetivo, aunque en el futuro sí podría evolucionar y pedirle que priorizara por ejemplo el color, objetos que se mueven de izquierda a derecha o que estén en el cielo, por poner un ejemplo", describe el físico.
El modelo considera el hecho de que un simple golpe de vista le basta al ser humano para distinguir lo esencial de lo superfluo en la escena que le rodea, interpretando así los elementos situados en el entorno según su grado de relevancia. Se trata de una asombrosa capacidad que usamos constantemente, y entre cuyos numerosas aplicaciones cotidianas figura, por ejemplo, la conducción de un automóvil. "Sólo los puntos fuertes de las imágenes que llegan a nuestros ojos son determinantes en el proceso de la visión humana, ya que no tenemos capacidad de interpretar todos los datos que se presentan a nuestro alrededor", explica el investigador.
De esta manera, nuestro sistema visual es el encargado de filtrar, a gran velocidad, la información capturada, prescindiendo de aquella que resulte irrelevante con el objetivo de hacer viable su posterior interpretación en el cerebro.
Esta capacidad humana de eliminar datos innecesarios o redundantes del entorno se conoce como 'atención visual'. Es un proceso aparentemente sencillo y transparente para el individuo que constituye, sin embargo, el resultado de un conjunto de mecanismos evolutivos extremadamente complejos a nivel óptico y neuronal.
"Si somos capaces de enseñarle a un robot a reproducir cada uno de estos pasos para lograr que aprenda a identificar las partes más relevantes de su entorno estaremos ante un avance importante; por ejemplo, comprimir vídeos y conseguir que pesen menos manteniendo la nitidez solo en las partes esenciales y distorsionando el resto, lo cual no quitaría valor a la pieza", apunta Leborán.
El trabajo que ha dado lugar a este algoritmo, desarrollado en el marco del Programa de Visión Artificial del centro, fue calificado en 2013 como "el mejor del mundo" en un estudio realizado por la University of Southern California. "Ahora tenemos que ver si merece la pena crear una spin off y sacar un producto comercial", concluye el físico compostelano.

Víctor Leborán | Físico del Grupo de Visión Artificial (USC)
"Nuestra vista distingue lo esencial de lo superfluo en un solo vistazo"








